Hello! I am a Master student and a member of Computer Vision Lab at Yonsei University advised by Prof. Bumsub Ham. I earned my B.S. degree in Intelligent Mechatronics Engineering from Sejong University in 2024.
My research interests include computer vision, network quantization, and efficient foundation models.
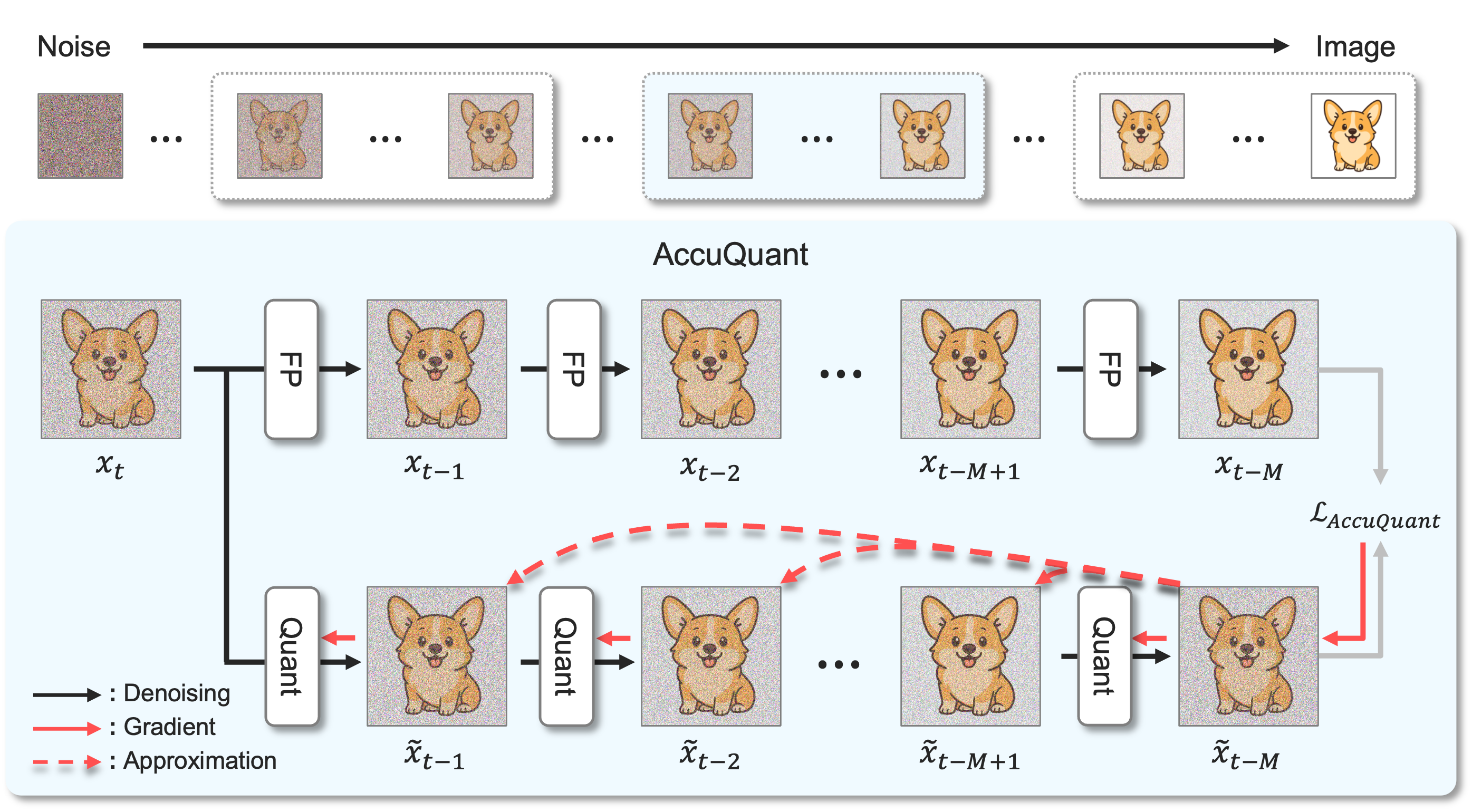
We present in this paper a novel post-training quantization (PTQ) method, dubbed AccuQuant, for diffusion models. We show analytically and empirically that quan3 tization errors for diffusion models are accumulated over denoising steps in a sampling process. To alleviate the error accumulation problem, AccuQuant mini5 mizes the discrepancies between outputs of a full-precision diffusion model and its quantized version within a couple of denoising steps. That is, it simulates multiple denoising steps of a diffusion sampling process explicitly for quantization, account8 ing the accumulated errors over multiple denoising steps, which is in contrast to previous approaches to imitating a training process of diffusion models, namely, minimizing the discrepancies independently for each step. We also present an efficient implementation technique for AccuQuant, together with a novel objective, which reduces a memory complexity significantly from O(n) to O(1), where n is the number of denoising steps. We demonstrate the efficacy and efficiency of AccuQuant across various tasks and diffusion models on standard benchmarks.
@inproceedings{lee2025accuquant,title={AccuQuant: Simulating Multiple Denoising Steps for Quantizing Diffusion Models},author={Lee, Seunghoon and Choi, Jeongwoo and Son, Byunggwan and Moon, Jaehyeon and Jeon, Jeimin and Ham, Bumsub},booktitle={Conference on Neural Information Processing Systems (NeurIPS)},year={2025},}
under review
Q-SAM: Quantizing Segment Anything Models
Seunghoon Lee, Jeongwoo Choi, Yura Seo, and 1 more author
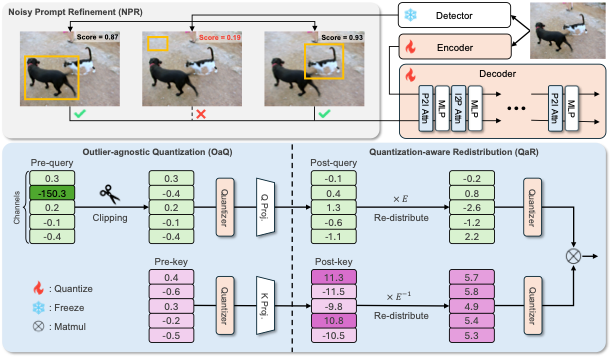
Post-training quantization (PTQ) aims to quantize a pre-trained full-precision model using a small set of unlabeled samples without training the weights. Although many PTQ methods show strong results on CNNs and ViTs, directly applying them to SAM results in performance degradation, mainly because the mask-decoder layers in SAM exhibit unique activation distributions. Specifically, we show that semantically meaningless outliers and large distributional gaps exist in the pre-query and post-key activations, leading to inefficient use of quantization levels in low-bit settings. We also show that the object detector often produces inaccurate calibration prompts, thereby providing unreliable guidance to the quantized model and further degrading performance. To address these issues, we propose a simple yet effective PTQ method for SAM, dubbed Q-SAM. We clip non-semantic outliers in the pre-query activations and redistribute the post-key activations so that quantization levels are allocated to regions where most values concentrate, enabling fine-grained quantization. In addition, we introduce an efficient indicator to filter inaccurate prompts without incurring additional computational overhead. Experiments on standard benchmarks demonstrate the effectiveness of Q-SAM, achieving state-of-the-art results at 4- and 6-bit settings. Our code will be made publicly available online.
@misc{lee2026qsam,title={Q-SAM: Quantizing Segment Anything Models},author={Lee, Seunghoon and Choi, Jeongwoo and Seo, Yura and Ham, Bumsub},booktitle={under review},year={2025},}
KoreaAI
Unsupervised Domain Adaptation Solving Class-Imbalance Problem on Semantic Segmentation
Seunghoon Lee*, Donghyeon Cho*, and Dongil Han
In 3rd Korea Artificial Intelligence Conference, 2022
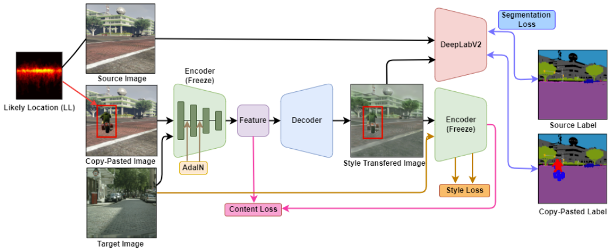
Deep learning models, which have been intensively studied in recent years, require a large quantity of data and paired labels in order to perform well. However, manually obtaining and labeling substantial amounts of data is quite expensive. In addition, even if the model is trained with such collected data, the model may not operate as expected due to domain shift, and it is difficult to expect good performance for the class if the amount of data collected per class is insufficient. In this paper, we propose applying a target domain style to the source domain, expecting the trained model without a target label to operate smoothly in the target domain, and using the Likely Location copy-paste method to solve the class imbalance problem for minor classes.
@inproceedings{lee2022uda,title={Unsupervised Domain Adaptation Solving Class-Imbalance Problem on Semantic Segmentation},author={Lee, Seunghoon and Cho, Donghyeon and Han, Dongil},booktitle={3rd Korea Artificial Intelligence Conference},year={2022},}